
https://arxiv.org/abs/2404.05657
Introduction
TransformerのSelf-attentionの部分は計算コストが非常高い。そこで、うまいこと削減できないか?と考える。
- Multi-head Attentionで複数のHeadが同じ視点でAttentionしてしまうこともあるので、そこらへんをどうにかしたくない?
各Attention BlockのAttention後の出力とそれをMLPにも入れた後の出力について、エントロピー(っぽい何か)を測ってみた。
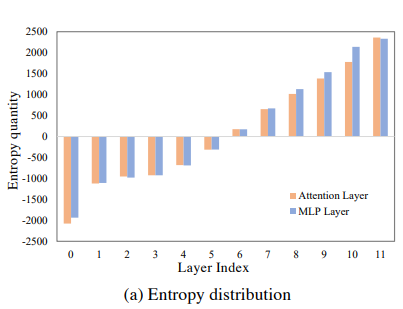
最初のほうのTransformerブロックでは、情報量は少ない!ならMLPでも十分代替できるのではないか!?という着眼点。
つまり、Attention→残差接続したものとFFN(中間表現にいったん圧縮してまた広げる)をやめて、FNNだけにする。
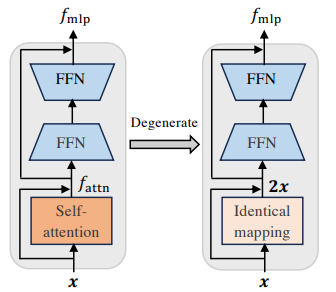
ただし、最初の数個のBlockと指定するだけではうまくいかない。お互いのブロック間の相互関係を無視して削除すると性能低下が著しい。
なので、事前に小さいデータセットで学習して、このようなデータセットならどのAttention Blockを消していいのか、という戦略で行く。
Related Work
- Swin Transformer
- すべての小さい画像のセグメントに対してAttentionすると計算コストが非常に大きいので、画像の局所性を利用して、切り分けたWindowの中でだけAttentionをしていくという有名なVision Transformerの改良版。
- MetaFormer
- AttentionがVision Transformerの性能強化を決定づけてるのではないとしている。うまいことTokenを混ぜればよいということだが、これはPooling Layerでも実現できるという主張。
- ToMe
- Transformerをするにあたって、似ているトークンをマージすることで全体のトークン量を減らせないか?
他にもToken Pruningと言って、不要なトークンを削減することで計算コストを下げるというものもある。
DynamicViT、Evo-ViTなど。
Method
Vision Transformer(ViT)について
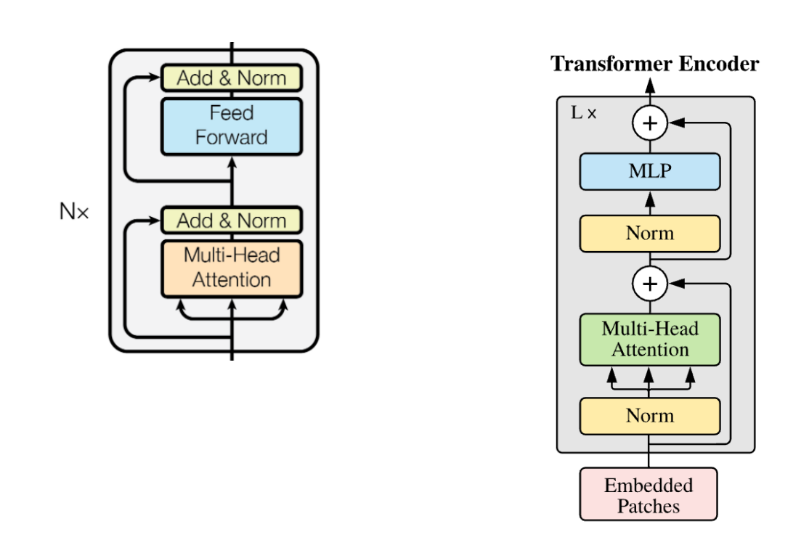
左が通常のTransformerのAttention Block。
- Multi-headでSelf-Attentionを行い、残差接続と併せて正規化。
- その入力をFeed Forward Network(FFN)に入れる。
- これは2層のMLPで、中間層の次元が小さいことから、うまいこと重要な情報を圧縮することを期待している。
右側がVision Transformer版のもの。ほとんど変わってないとわかる。
EncoderのAttention Blockの出力(右側)は以下のように書くことができる。
内部表現に対してのEntropyっぽい何か
Entropyといったが、内部表現の情報量の多さについて何かしらの尺度が必要。
ここでは、かなり強引だが、すべての内部表現はガウス分布に従い分布されるという仮定を基にする。そして、データから期待値と分散を計算できる。
以下のように、1つのHeadのAttention結果について、標準偏差のlogをEntropyっぽい何かとして扱い代用する。
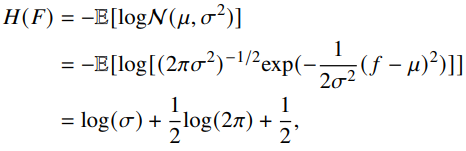
最終的には、すべてのMulti-headチャンネルについての標準偏差のlogを合算することで、Entropyっぽい何かとして計算される。
Attention Blockの相互作用
では、単純に内部表現のEntropyっぽい何かが低いBlockから削除すればいいかというと、それは他のBlockとの相互作用を無視するので、重要な手掛かりまでうっかり消してしまうかもしれない。
したがって、情報量の考え方を元に、Transfer Entropy(TE)というものを考える。これは、自分のBlockの情報量から、自分を除いたすべてのBlockとの相互情報量を引いた値である。
この値が小さい=他のBlockの情報から十分に復元できるので、消してもあまり問題がない。という感じで削除の指針とする。
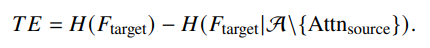
Attention Blockの希釈について
Attention Blockを消すときは、いきなり消すと影響が出るので、訓練が終わりに近づくにつれて、どんどんAttention Blockの出力が影響を及ぼさないようにする、という風に考えている。
というスパースマスクを設計し、
はらだのへんじまち!
Algorithmの流れ

- まずは小さいデータセットで、どのAttetnion Blockを外していいのかを見つける。
- 外したいものはに入れ、残すものはに入れる。
- 本番の訓練を始める。この時、は訓練が進むにつれてスパースマスクのがどんどんに近づくようにして、Attentionの影響を減らす。
- 最後に推論するときは、に含まれるAttetion Blockはそもそもなかった扱いする。これによって推論時のメモリ節約ができるようになる。
Experiments
- DeiT-BというViTのものを用いて、ImageNet-1Kで学習する。
- 細かい領域分割タスクの評価のため、ADE20Kで評価する(これはセグメンテーションのデータセット)
- DeiT-Bは事前にCIFAR-100で事前学習させたものをFine-tuneしたらしい。
実験の結果
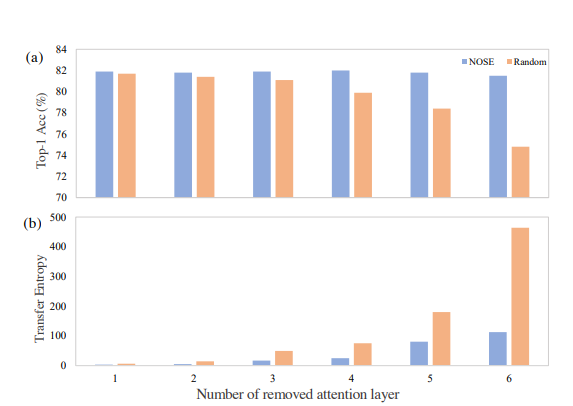
想定通り、RandomにAttetnion Blockを落とすより、情報理論的に落とすものを選び、スパースマスクを乗じて徐々に影響を減らすほうがAccuracyもよく、保持してる情報量も段違いに多かった。
特に、DeiT-Bの12個あるEncoderのAttention Blockのうち6個を落としても、性能はほぼ変わらず横ばいだった。